The last few years have seen tremendous improvements come out of the domain of artificial intelligence (AI), specifically with deep learning but more specially natural language processing (NLP).
At the core of several breakthroughs, one innovation is involving LLM (Large Language Model) embeddings. Such embeddings enable machines to understand human language more accurately in the right context than ever before.
If you have used anything to talk like a voice assistant, search or chat with text on your device side during this time, chances are high that benefits by LLM embeddings were available to you without even noticing. But what are they? How do they work? So, why are they necessary for AI?
In this blog, we will take you through the basics of LLM embeddings and how machines are processing human language with these sophisticated techniques.
What Are LLM Embeddings?
Let’s start by deconstructing the word “embedding”. Embeddings are vector representations of text or data in AI. In short, they translate text into numeric representations so machines can understand and act on it. Word embeddings are not a new idea by any means.
Older models such as Word2Vec and GloVe mapped words to vectors, which was used by the early model to learn word relationships. But these models were restricted—they could not understand the sense of a word as determined by its context. However, LLM embeddings produced using Large Language Models such as GPT or BERT and other transformer-based models.
Consequently, the embeddings these models use are contextualized embedding (i.e. word has meaning which is dependent on its sentence or the conversation it belonged to). For example, in a statement that goes like: “He went to the bank to deposit money,” the interpretation of “bank” is based on whether it refers to an entity where financial services are rendered.
For example,
- In “I sat on the banks of a river,” the word bank refers to distance between where I was and where water begins.
- Whereas, in “She sat by the river bank,” here also too it’s edge which later would mean her resting place is none other than riverside our beach etc.
Key Differences Between LLM and Traditional Embeddings
- Contextual Understanding: Traditional embeddings assign fixed vectors to words, while LLM embeddings adjust based on surrounding words and phrases.
- Depth of Meaning: LLM embeddings capture deeper meanings, including nuances, intent, and relationships between complex concepts.
- Flexibility: LLM embeddings can be fine-tuned to specific domains, making them more adaptable.
How Do LLM Embeddings Work?
Now that we get what LLM embeddings are, let’s see how they do it. It breaks down the process into multiple steps.
Step 1: Input Tokenization
In other words, before a large language model (such as GPT-2) could generate embeddings, it needs to parse/comprehend/parse the text for its tokens. Tokenization divides the sentence into words, subwords, or characters as per model.
For example, the sentence “The dog barked” might be tokenized into:
- [“The”, “dog”, “barked”].
These tokens become the input to the model.
Step 2: Transforming Text into Vectors
Once tokenized, the LLM uses its transformer architecture to transform each token into a high-dimensional vector. These vectors are essentially a list of numbers that represent the meaning of the token.
For word embeddings with vectors, each aspect of its meaning (part of speech, context in other words, or in sentence) is encoded as dimensions. A transformer utilizes the self-attention mechanism to learn the importance of each word with respect to every other word in a sentence.
The background adds the possibility that context can be caught in a way it couldn’t using earlier models. This is because the word “her” can refer to two different people, as in the sentence, “She gave her friend a book.” The presence of surrounding words in the case above makes it clear which “her” is being referred to, with a little help from our friend, i.e., the transformer model helps clarify that.
Step 3: Understanding Context
Context is what makes LLM embeddings so powerful. They do not just reflect a single word type; instead, they change and affect the patterns of other words that surround them.
For example, if you take a word like “run” and put it in sentences as different as “He went for a run” vs “The company is running a promotion,” the embeddings will look different. The model sees a sentence (or even a paragraph) at once and chooses the optimal vector for each token to capture the full context of the text.
Why LLM Embeddings Are Important?
LLM embeddings have transformed NLP in profound ways. Here’s why they are so important:
1. Contextualized Language Representation
As mentioned, LLM embeddings capture the meaning of a word or phrase based on its context. This makes them vastly more accurate than previous models.
We all know how language can trip us up, and it is not just because words have more than one meaning. It also shows that context matters when trying to understand them.
LLM embeddings help in two ways: first, they ensure that a language model can understand not just individual words but also the relationships between those words and their meaning within an entire sentence, paragraph, or document.
2. Applications of LLM Embeddings
LLM embeddings are behind many of the cutting-edge NLP applications we use today:
- Machine translation: Thanks to improvements in embeddings for context, tone, and meaning, models such as Google Translate are more accurate than ever.
- Sentiment analysis: LLM embeddings help identify whether a text (like customer reviews) is positive, negative, or neutral.
- Content generation: LLM embeddings result in coherent, contextually fitting content generated via tools like OpenAI’s GPT-4.
- Search and recommendation systems: Embeddings enable search engines like Google to deliver much more relevant results based on the actual meaning behind a query, not just the individual words.
3. Scalability for Large Datasets
LLM embeddings are also highly scalable, which makes them ideal for large datasets. They allow models to process massive amounts of text efficiently, making them suitable for tasks like document classification or question-answering systems that require a deep understanding of content.
4. Adaptability Across Domains
Another reason LLM embeddings are so powerful is their adaptability. You can fine-tune LLMs to specific industries or tasks, like healthcare diagnostics or legal text analysis. This means the embeddings can be tailored to fit specific use cases, making them incredibly versatile.
Examples of LLM Embeddings in Action
1. Real-World Applications
The importance of LLM embeddings is reflected in many of today’s AI applications. Let’s look at a few examples:
- Google Search: Google’s search algorithms rely heavily on LLM embeddings to provide relevant results. By understanding the context behind a query, Google can surface the most appropriate answers, even when the query is vague or ambiguous.
- Chatbots and Virtual Assistants: AI assistants like Siri and Alexa use LLM embeddings to understand your questions and provide relevant, context-aware responses. Without these embeddings, responses would often be inaccurate or off-topic.
2. Case Study: Enhancing Search and Recommendation Systems
Take Netflix, for example. The platform uses LLM embeddings to improve its recommendation system. By analyzing user preferences and the context of what users watch, Netflix can recommend shows and movies that align with their tastes. LLM embeddings make this contextual understanding of both content and users possible.
How to Get Started with LLM Embeddings?
For those looking to explore LLM embeddings, several popular tools and models make it easy to get started.
1. Popular Tools and Models
Some of the most commonly used models for generating embeddings include:
- GPT (Generative Pretrained Transformer): Developed by OpenAI, GPT models are widely known for their ability to generate content and complete text.
- BERT (Bidirectional Encoder Representations from Transformers): BERT is another popular model that focuses on understanding context by looking at both the left and right sides of a word or phrase.
- Hugging Face: This is a popular library for implementing transformer models. It offers pre-trained models like GPT and BERT, along with easy-to-use APIs.
2. Practical Guide
Here’s a simple way to generate embeddings using Hugging Face:
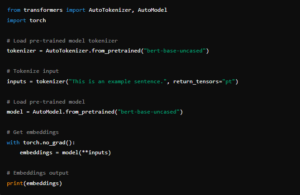
This basic code loads a pre-trained BERT model and tokenizes a sentence to generate embeddings. You can use these embeddings for various tasks like sentiment analysis, classification, or even search optimization.
3. Fine-Tuning for Specific Tasks
Fine-tuning allows you to tailor LLM embeddings to specific needs. For example, you can fine-tune a model for medical text analysis, giving it a better understanding of healthcare-related language.
Conclusion
LLM embeddings are reshaping how machines process and understand human language. Not only do they capture context and meaning, but also power various tools and applications, from search engines and virtual assistants to content generation and recommendation systems today.
Their adaptability, scalability, and strong contextual understanding make them essential in AI and NLP. The way we converse with machines and make them understand our text will be driven by the use of LLM embeddings, onto which advances in tech will continue to feed.
In a world where understanding language is key to unlocking insights and providing value, LLM embeddings are truly revolutionizing the way we communicate with technology.
VisionX’s machine learning development services can be a valuable partner, helping you integrate advanced AI models into your products to deliver better user experiences and drive innovation.