It is hard to judge the output of an AI model, especially when the answers are creative, complex, or in response to open-ended questions. Even though human review is useful, research shows it costs 10- 100x more than automated evaluation while only providing marginally better consistency.
The idea of LLM as a judge has grown because of this. This technique uses large language models to test other models, and it’s a cheaper and more scalable option than doing reviews by hand. The model is both the creator and the critic.
The irony is hard to miss: the same models that need oversight now help provide it. But it works. With the right setup, an LLM evaluator can flag weak outputs, compare options, and surface helpful feedback at scale.
In this guide, you’ll learn how to apply LLM-as-a-judge in real-world evaluation tasks, what works, what doesn’t, and how to get started with better model assessment at scale.
What is “LLM-as-a-Judge”?
LLM-as-a-Judge is a method that uses Large Language Models (LLMs) to assess, score, or analyze outputs from other LLMs. It handles tasks such as text generation, question responses, and logical reasoning.
The LLM acts as an automated evaluator that measures quality based on set criteria like accuracy or coherence. This removes the need for human judges in some cases.
This approach is used for grading, comparing AI models, or filtering harmful content. It helps assess open-ended tasks where traditional metrics fail.
With the right evaluation criteria and judgment prompts, LLMs can assess tone, clarity, and helpfulness. It’s a practical solution for teams working on LLM-powered applications.
Why Do We Need LLMs to Evaluate LLMs?
Judging the output of a large language model is not a simple task. In many cases, there’s no clear reference answer, and different responses can all feel correct depending on their tone, structure, or usefulness.
Most traditional LLM performance metrics usually miss the mark. They may track overlap with expected outputs but fail to capture real-world quality, like whether the response makes sense or adds value.
Even though human evaluation handles nuance well, it also demands time, effort, and budget. Reviewing thousands of outputs by hand does not scale, especially in fast-paced development cycles.
As the LLM market is expected to reach USD 69.83 billion by 2032, growing at a CAGR of 35.1%, the need for scalable evaluation methods becomes even more critical. With LLM-as-a-judge, organizations can efficiently evaluate outputs, guaranteeing quality and consistency at scale without the high costs of manual reviews.
How LLM-as-a-Judge Works?
To use LLM-as-a-Judge effectively, you need a structured process that defines what to evaluate, how to prompt, and how to interpret results.
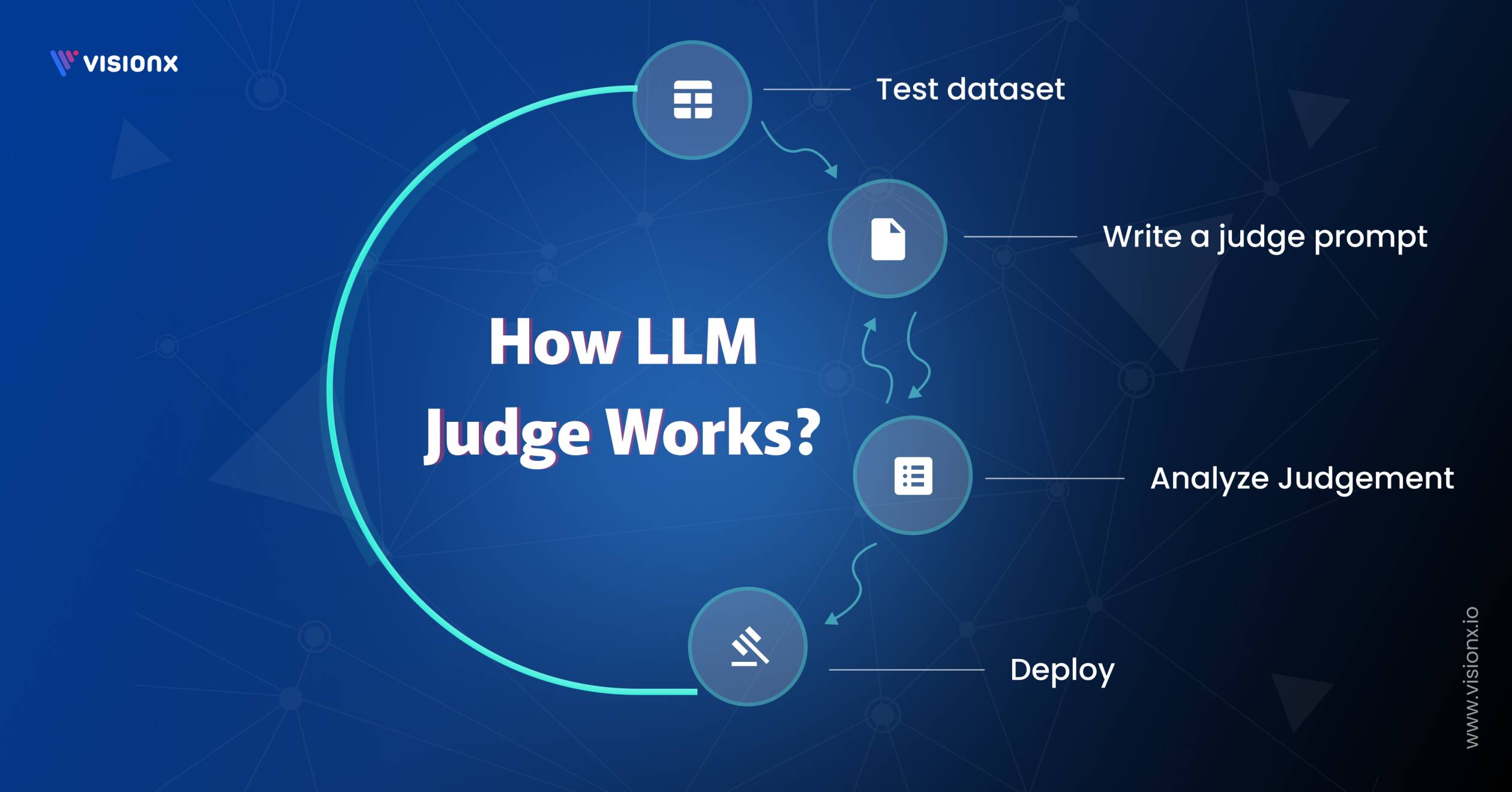
A. Define the Evaluation Task
Decide what to test: helpfulness, reasoning, or alignment with intent. Set clear evaluation criteria based on the goals of your product. This step lays the groundwork for the evaluation of large language models.
B. Design a Judge Prompt
Build a precise judge prompt that guides the model to assess quality. Include the task, context, and a reference answer where relevant. Strong prompts reduce drift and improve reliability across evaluation tasks.
C. Present the Output for Judgment
Feed the generated output into the LLM along with the prompt. Use tools like MT-Bench or Chatbot Arena to automate comparisons. This step supports judging LLM-as-a-judge with MT-Bench and Chatbot Arena at scale.
D. Analyze and Use the Feedback
Review scores, rankings, and reasoning from the LLM evaluator. Use this data to adjust model behavior or plan a fine tune step. The result is a scalable, repeatable insight that is close to human judgment.
Types of Evaluations LLMs Can Perform
Understanding how to evaluate LLM output requires structured methods that balance accuracy, nuance, and consistency. Three common evaluation types help define this process and are widely discussed in research.
1. Pairwise Preference (A vs B):
This method presents two outputs side by side. The LLM evaluator selects the better one based on clarity, relevance, or alignment with intent. Platforms like MT-Bench and Chatbot Arena use this format for judging LLMs, enabling fair and scalable comparisons.
2. Direct Scoring (Likert Scale):
Here, the model assigns a score, usually from 1 to 5, to a single response. This approach helps quantify output quality using consistent LLM performance metrics, though it may miss subtle context shifts.
3. Rubric-Based Evaluation (Structured Grading):
This format involves fixed criteria such as accuracy, tone, and coherence. The model checks if the output meets each standard. This method mirrors human evaluation closely and works well in both academic and production use.
Prompt Engineering for LLM-as-a-Judge
The quality of LLM as a judge’s output depends heavily on prompt engineering. To ensure accurate and unbiased evaluation, the prompt structure must align with the task, the evaluation criteria, and the format used, whether pairwise, scoring, or rubric-based.
A good evaluation prompt defines the model’s role, the task at hand, and the scoring logic. For example, a prompt may ask the model: “Which response better answers the question below? Provide a short reason.” This format suits judging LLM-as-a-judge with MT-Bench and Chatbot Arena, where clarity and consistency matter.
Clarity in the judge prompt helps the model avoid vague or repetitive feedback. Phrasing must avoid open-ended cues and instead give a direct frame, such as evaluating for helpfulness, relevance, or tone. Avoid ambiguous language to make sure the evaluation model produces consistent and valid outputs.
Knowing how to evaluate LLM output starts with shaping a prompt that keeps the model grounded in task goals. Better prompts lead to better scores and more reliable LLM performance metrics.
How to Create an LLM judge?
An LLM judge is a model created to evaluate generated outputs based on explicit tasks, prompts, and score logic. Many teams currently use it to develop a dependable evaluation system at scale.
1. Define the Evaluation Task
Start by specifying what the LLM judge must assess, this could include summary quality, question-answer accuracy, or chatbot tone. Set the evaluation criteria, such as relevance, clarity, or coherence, to ensure alignment with the goal.
2. Select or Fine-Tune the Evaluation Model
Choose a capable large language model (e.g., GPT-4) for judgment. For more domain-specific needs, consider a fine-tune step using labeled examples to improve its ability to mirror human judgment across complex evaluation tasks.
3. Craft the Judge Prompt
Design a clear, task-focused evaluation prompt. Whether for pairwise preference, scoring, or rubric checks, the prompt must reflect the context and desired output. Refer to the LLM as a judge paper or setups like MT-Bench and Chatbot Arena for proven structures.
4. Present the Input and Reference Answer
Feed the model the generated output, input query, and, if available, a reference answer. This helps the LLM compare, assess, and decide based on ground truth.
5. Score and Analyze Outputs
Collect the model’s judgment and assign scores. Use defined LLM benchmarking performance metrics to analyze trends and evaluate consistency. Aggregate results across tasks for benchmarking.
Benefits of Using LLM as a Judge
LLM-as-a-Judge lets teams use large language models to assess the quality, accuracy, and structure of generated output across different tasks. As interest grows in how to evaluate LLM systems, this approach helps shape a clearer and faster evaluation process for lab settings and real-world use.
- Scalability:
LLMs assess large volumes of data at once. This allows teams to handle broad evaluation tasks that would take much more time with human reviewers.
- Consistency:
LLMs apply the same logic to each result. This helps reduce the kind of variation often found in human judgment.
- Lower Cost:
Using an LLM in place of manual review helps cut costs, especially in cases that need expert-level decisions or many review rounds. In fact, one study showed invoice checks dropped from $4.27 to just cents per item.
- Multiple Focus Areas:
LLMs can judge many evaluation criteria in a single pass, like accuracy, relevance, and tone, without needing extra tools or steps.
Limitations of Using LLM as a Judge
While the LLM as a Judge approach improves speed and consistency, it also introduces several important limitations that must be addressed for reliable assessments:
- Bias and Hallucination:
A large language model may reflect or amplify bias from its training data. It may also produce evaluations based on hallucinated facts rather than ground truth or a valid reference answer.
- Overconfidence in Outputs:
LLMs often provide confident scores or judgments, even when they are incorrect. This can mislead teams unless supported by a strong evaluation metric or human comparison.
- Limited Domain Expertise:
Without fine-tune steps or domain-specific prompts, general-purpose LLMs may fail to judge specialized content accurately, such as medical or legal texts.
- Prompt Sensitivity:
The quality of evaluation depends heavily on the judge prompt. Slight changes can lead to different results, reducing trust in reproducibility.
When Not to Use LLM as a Judge with Mitigation Tips
While LLM-as-a-Judge provides significant advantages in speed and scalability, there are scenarios where its use is not suitable. Below are some key situations and suggestions for mitigation:
- High-risk domains: In critical areas like medicine, law, or safety, wrong judgments can have serious consequences.
- Tasks with deep context: LLMs miss cultural, historical, or nuanced context that humans can easily understand.
- No clear ground truth: Without a reference answer or established ground truth, LLMs may produce biased or inaccurate evaluations.
- Adversarial tests: LLMs might fail to spot hidden flaws or misinterpret edge cases in testing scenarios.
- Prompt instability: Small changes in the judge prompt can cause variations in results, undermining consistency.
Mitigation Tips
- Use domain experts or certified human reviewers for critical evaluations. LLMs can assist but should not replace human judgment.
- Rely on human evaluators who understand the context. LLMs should only support, not make final decisions.
- Establish clear reference answers and ground truth before using LLMs. If none exist, stick to manual review or alternative methods.
- Use structured testing methods or third-party audits for adversarial testing. Avoid relying solely on LLMs for edge-case evaluations.
- Test multiple judge prompts and average the results. Use LLMs for auxiliary support, ensuring outcomes align across variations.
Metrics for Measuring LLM Evaluation Effectiveness
How can we tell if an LLM-as-a-Judge is doing its job well? Researchers typically compare their scores to human ratings. A high correlation between the two indicates reliability. Consistency tests check whether the LLM provides similar scores over time, while reproducibility measures how steady the evaluation is across different datasets. Studies show that LLMs can match human judgment better than traditional metrics in many cases.
Best Practices to Follow
When using LLM-as-a-Judge, a few best practices can help make sure the process runs smoothly and the results stay accurate. Here are some tips to keep in mind;
Use Multiple LLM Judges for Consensus
Don’t just rely on one LLM-as-a-Judge. It’s like getting a second (or third) opinion; having multiple LLMs weigh in can help you get a more balanced result. It reduces the chance of bias and gives you a clearer picture.
Benchmark Against Human Evaluations Initially
It’s always good to start with a baseline. Compare the LLM evaluator to human assessments early on. This way, you’ll know if the LLM performance metrics are on track and if the system is providing judgments similar to what a human would.
Log and Review Outlier Scores
Keep an eye on those weird, outlier scores. If something’s off, it could be a sign of a deeper issue with the model. By reviewing them regularly, you can tweak the system and make sure the evaluation process stays smooth and consistent.
Future of LLM-based Evaluation
The future of LLM-based evaluation will likely involve agentic evaluation pipelines, where LLMs autonomously assess and improve other LLMs by dynamically adjusting their evaluation processes. These pipelines will enable constant optimization without the need for human intervention, making the assessment process more streamlined.
In addition, LLMs evaluating multimodal outputs will become more common, allowing models to judge not just text but also images, audio, and video. This will help deliver richer and more accurate assessments.
Another thrilling new trend is LLMs auto-tuning other LLMs, in which an LLM fine-tunes another using evaluation feedback. So that models become more specialized and better over time, with improved overall performance and adaptability across domains.
Build Smarter LLM Evaluation Systems with VisionX
If you’re looking to set up a solid LLM as a Judge system, VisionX can make the whole process smoother:
- Custom LLM Fine-Tuning: VisionX can fine-tune LLMs to correctly assess certain tasks, whether it is legal, healthcare, or any specialty area, making sure that the model’s judgment best aligns with the needs of real-world scenarios.
- Multi-Modal Evaluation Setup: Want your LLMs to assess not just text but also images, audio, or videos? We have the expertise to integrate computer vision solutions and other AI models to evaluate multimodal outputs, providing richer insights.
- Automated Evaluation Pipelines: VisionX can build agentic evaluation pipelines where LLMs evaluate and improve other models automatically, enhancing efficiency and optimizing performance without manual oversight.
- Ethical and Bias Audits: Our platform is also great at identifying and mitigating bias in models, ensuring your LLM evaluator delivers fair and transparent results.
Don’t settle for average. Contact VisionX today to build a more reliable and efficient LLM-based evaluation system that meets your needs.
What is LLM-as-a-judge translation?
LLM-as-a-judge translation refers to using Large Language Models (LLMs) to evaluate and translate the quality of outputs from other models. Rather than relying on human evaluators, LLMs assess the accuracy and relevance of generated content as automated judges.
What is relevance in LLM as a judge?
Relevance in the LLM-as-a-judge context refers to how well the LLM’s evaluation aligns with the task at hand. It measures if the judgment considers key aspects such as correctness, context, and completeness of the output.
What is the LLM-as-a-judge paradigm?
The LLM-as-a-judge paradigm uses LLMs to assess the performance of other models. LLMs replace human judgment by evaluating outputs based on specific metrics, which makes the evaluation process faster while maintaining consistency.
Do you need an LLM to be a judge?
Although it is not necessary to employ an LLM as a judge, it has advantages like scalability and consistency. For large-scale evaluations that are needed for tasks, LLMs are a good choice, but human intervention is still worth it for complex or ethical decisions.
Can an LLM judge for bias?
Yes, LLMs can help detect bias in outputs by identifying patterns in data. However, their effectiveness depends on the quality of the training data. Combine LLM evaluations with human oversight to ensure a more accurate and fair assessment.