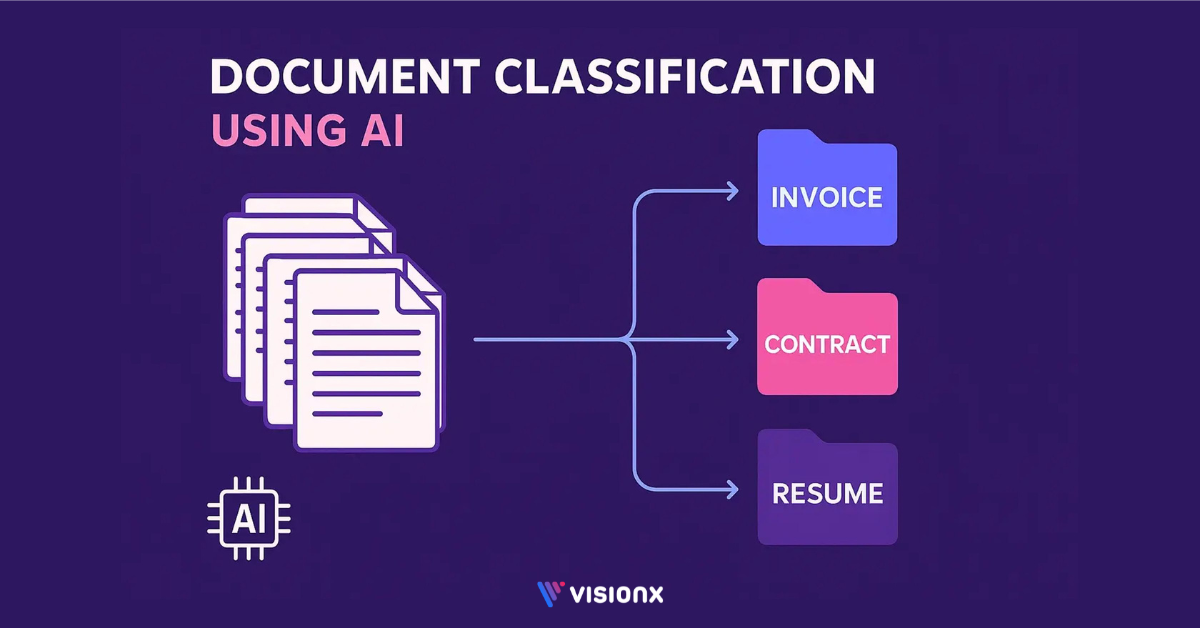
Most organizations deal with a flood of documents, contracts, invoices, reports, and forms. Sorting them by hand takes time, leads to mistakes, and slows down work. As more files come in, teams often lose track of key information.
To solve this, most businesses currently use AI document classification. By using AI, companies can organize and categorize documents according to their content easily and with a much higher degree of accuracy. It eliminates manual effort and saves teams time so they can devote it to better things.
In fact, a recent McKinsey survey found that 72% of organizations had adopted AI in at least one business function, up from just 55% not long ago.
AI facilitates system organization, regardless of whether the files are digital or scanned. We’ll go over how it functions, why it matters, and how to apply it in your company in this guide.
What is Document Classification?
AI Document classification refers to the process of automatically categorizing documents based on their content. It uses AI and ML algorithms to analyze text, structure, and layout to determine the document’s type.
This is particularly useful for managing large volumes of unstructured data efficiently. It improves speed and accuracy when dealing with large volumes of documents.
There are four classifications of documents, such as;
- Invoices: for financial transactions
- Legal documents: like contracts and court papers
- Contracts: agreements with clients or vendors
- Emails: sorted by department, topic, or priority
Comparing Traditional and Automated Document Classification
Traditional document classification relies on people to read, sort, and label documents by hand. This method often causes delays, errors, and inconsistent results. It also falls short when dealing with large volumes of files.
In contrast, automated document classification uses AI tools to review content and assign each file to the right category. With machine learning for document classification, the system learns from data to improve how it sorts over time. It handles tasks quickly, with fewer mistakes, and works well at scale.
While manual sorting may fit small tasks, it fails to keep up with modern demands. Automated systems deliver accurate classification, save time, and allow teams to shift focus to more important work.
Benefits of Implementing AI Document Classification
Using AI for document classification gives businesses an edge in managing large amounts of data. Here are the key benefits:
- Faster processing: AI tools sort thousands of files in minutes. This helps teams avoid delays and complete tasks like billing or approvals much faster than manual methods allow.
- Improved accuracy: AI reduces mistakes by following set rules and patterns. This leads to more reliable results and fewer errors when placing documents into the right categories.
- Support for scanned files: With OCR document classification, AI can handle printed or handwritten documents. This helps convert physical files into digital records that are easier to store and find.
- Enhanced security: AI detects files with classified information or sensitive content. This helps protect important data and keeps unauthorized users out.
- Flexibility and growth: AI systems adjust to growing workloads without losing speed or accuracy. Businesses don’t need to add more people as file volume increases.
Types of Document Classification
Document classification can take different forms based on how documents are grouped and what methods are used. Here are the main types:
1. Rule-Based Classification:
This approach applies fixed rules, keywords, or patterns to categorize documents. For instance, documents containing the word “invoice” are categorized in the finance department. It is effective when content is organized or has predictable formats, but not with unstructured documents. It’s often used for simple, document-based classification tasks.
2. Automated Document Classification:
Automated document classification employs advanced machine learning models, like deep learning and natural language processing (NLP), to automatically categorize documents based on content. This method works by training the model on large datasets to recognize context, relevance, and patterns. It’s highly scalable and saves time by automating the categorization of large volumes of documents.
3. Visual Classification:
Visual classification is dedicated to document classification based on physical attributes such as layout, appearance, and visible patterns (i.e., tables, logos). It is popular in situations when documents have structured data or graphical hints that inform about their class.
Methods of AI Document Classification
AI document classification uses machine learning for automatic categorization of documents. Here are the main methods of document classification using machine learning;
Supervised Classification:
Machine learning for document classification involves training a model on labeled data. The system learns patterns from labeled examples and classifies new documents correctly. The approach is suitable for such tasks as document classification, invoices, or contracts. The more data the system processes, the higher its classification accuracy.
Unsupervised Classification:
Unlike supervised techniques, unsupervised classification does not need labeled data. But instead, the system applies clustering algorithms to identify inherent patterns in the data. This technique is helpful when documents are unstructured or categories are not pre-defined. It is commonly applied for classifying documents where manual labeling is not feasible.
Semi-Supervised Classification:
This method of AI document classification is a blend of supervised and unsupervised approaches. It uses a small set of labeled data and a large set of unlabeled data. It helps create scalable machine learning models for real-world data and increases accuracy without the high expense of comprehensive labeling.
How AI and OCR Work Together for Efficient Document Classification?
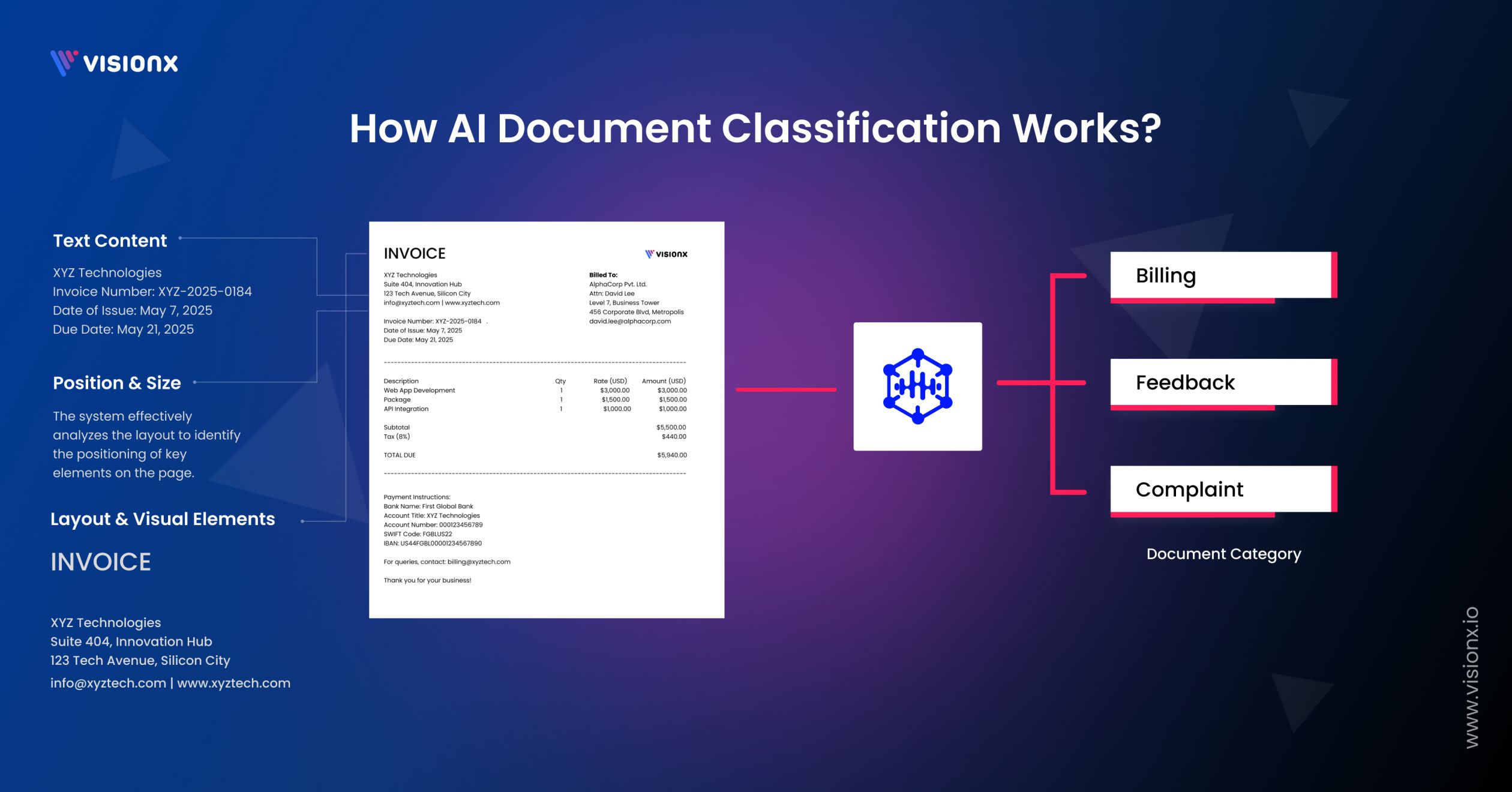
OCR and AI combine to enhance automatic document classification. Machine-readable text is produced from scanned photos or PDFs using optical character recognition. Following extraction, AI algorithms categorize documents according to their content using machine learning.
Natural language processing (NLP) is used by AI systems to evaluate the retrieved text and determine its meaning and context. These models can gradually improve their performance because they are trained on training data. As a result, human labor is reduced, and documents like reports, contracts, and invoices are quickly sorted.
The integration of OCR and AI makes document processing faster, more efficient, and ensures correct classification. This technology allows companies to process large numbers of documents efficiently. It enables companies to process classified information with speed and accuracy.
How does Automated Document Classification Work?
AI and machine learning are used in automated document classification to effectively sort documents. To guarantee accuracy and speed, the procedure is divided into multiple steps.
1. Data Collection:
Collecting digital documents or scanned photos is the first step. These could be contracts, emails, bills, or other types of paperwork. At this stage, the system collects and organizes the inputs before they enter the classification pipeline.
2. Text Extraction (OCR):
Text can be extracted from scanned photos or PDFs and converted into machine-readable text using optical character recognition (OCR). This step enables the document content to be analyzed further by AI systems.
3. Preprocessing:
The extracted text is cleaned and standardized. Irrelevant information is removed, and the text is formatted to prepare for classification. Proper preprocessing improves the performance of the machine learning models used in document classification.
4. Document Classification Using AI:
AI models, often based on machine learning, analyze the document’s content and categorize it into predefined classes. Machine learning for document classification enhances accuracy and improves model performance over time.
5. Post-Processing and Integration:
After classification, documents are directed to the appropriate systems for storage, approval, or further processing. Automated document classification ensures fast and accurate document handling, saving time and reducing errors.
How to Build a Document Classifier using Python?
Building a document classifier in Python involves several clear steps:
A. Set Up the Environment:
Install necessary libraries such as scikit-learn, pandas, and nltk for machine learning, data handling, and natural language processing (NLP).
pip install scikit-learn pandas nltk
B. Collect and Preprocess Data:
Collect a labeled dataset with documents categorized into classes (e.g., invoices, contracts). Clean the data by removing stop words, punctuation, and irrelevant content. You can use NLTK for tokenization and stop word removal.
from nltk.corpus import stopwords
stop_words = set(stopwords.words(‘english’))
C. Feature Extraction:
Convert the text into numerical features using methods like TF-IDF (Term Frequency-Inverse Document Frequency) or CountVectorizer from scikit-learn.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(stop_words=’english’)
X = vectorizer.fit_transform(documents)
D. Train the Classifier:
Select a machine learning model such as Logistic Regression, Naive Bayes, or SVM. Train the model on the preprocessed dataset.
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB()
model.fit(X_train, y_train)
E. Evaluate the Model:
Test the classifier on unseen data to check its accuracy and adjust the model as necessary.
accuracy = model.score(X_test, y_test)
print(f”Accuracy: {accuracy * 100:.2f}%”)
Challenges Faced in Automated Document Classification
While automated document classification is efficient, there are a number of drawbacks. An outline of typical problems and solutions lies here:
Data Quality Problems:
Poor data quality, such as missing or irrelevant information, can influence the AI model’s performance. To overcome this, clean up and preprocess the data so it is accurate and relevant. Proper data preparation is necessary for AI document classification as well as ensuring the correct classification of documents.
Managing Multiple Types of Documents:
Classification is made more difficult by the fact that documents can come in a variety of formats, including PDFs, pictures, and handwritten text. Scannable documents can be transformed into machine-readable text with the use of OCR document classification. Systems can handle a variety of document types with ease when OCR is integrated with automatic document classification.
Class Imbalance:
When some categories consist of fewer samples, the model can struggle to classify them correctly. Solutions to such a situation include class weight tuning, oversampling, or undersampling. It is done to enhance machine learning model performance and promote balanced categorization for all document types.
Top Use Cases of AI Document Classification
AI document classification transforms how organizations manage large volumes of files. In finance, automated document classification reduces invoice costs by up to 70% while improving accuracy. Top banks now use machine learning for document classification to handle thousands of contracts in seconds.
In healthcare, hospitals reach 95% accurate classification when sorting patient records. These systems rely on strong learning models and large training datasets,15+ hours per week in administrative work. This helps clinicians focus more on patients and less on paperwork.
Legal firms cut review time from hours to minutes by applying intelligent document processing. This allows them to handle millions of classified information records each year without compromising quality.
In logistics, global carriers now move past shipping delays with the help of OCR document classification. These tools speed up customs processes by 80%, allowing companies to handle high volumes of document-based records with ease and precision.
AI Document Classification Best Practices
Adopting AI document classification requires more than a model; it demands structure, real-world insight, and flexibility. Here’s how to build a process that scales and performs well:
1. Focus on Document Purpose, Not Just Format:
Understand what the document does. Whether it’s an invoice, contract, or compliance form, classify based on context and content. This helps the machine learning model pick up deeper meaning, not just layout patterns or keywords. This method is especially beneficial in industries such as law and finance, where precision and context matter more than the format.
2. Combine AI with Rule-Based Logic:
Use rule-based systems for strict requirements and let AI handle nuance. For example, flag any document with a specific clause using rules, while the AI handles broader text classification. This hybrid approach ensures you get the benefits of both precision (from rules) and scalability (from AI).
3. Train on Imperfect, Real-World Data:
Use scanned documents, messy text, and inconsistent layouts in your training dataset. AI learns best when exposed to inconsistencies, such as handwriting, blurry text, or unusual layouts, so that it can adapt to a wide range of potential inputs. This improves model robustness and model performance over time.
4. Keep a Human in the Loop:
Regular human checks catch errors, improve quality, and provide feedback. Especially early on, humans guide AI and flag edge cases it may miss. This feedback loop helps refine the model and improves overall accuracy. This approach is crucial during the model’s initial deployment and helps improve both the training data and the model’s long-term accuracy.
5. Plan for Scale and Evolution:
Document types and business needs evolve. Choose automated document classification systems that can adapt to changes, such as new document types or regulatory updates. Flexibility ensures long-term success and the ability to scale as needed.
How VisionX Brings Precision to Document Classification
VisionX provides powerful AI-driven solutions to enhance your document classification processes. We develop custom AI document classification models that sort documents with high precision and speed, improving operational efficiency.
Our expertise in machine learning ensures your system can accurately categorize a variety of document types, including contracts, invoices, and emails.
We combine OCR with AI to process both digital and scanned documents seamlessly. With our tailored services, you can focus on building robust document classification workflows and optimizing models for better document handling.
We focus on delivering solutions that save time, enhance accuracy, and ensure secure handling of classified information.
Looking to level up your document processing and accuracy? Let’s chat about how VisionX can support your goals.
FAQs
How to use AI to classify documents?
First, gather your documents and use OCR if they’re scanned. Clean the text and feed it into a machine learning model trained to sort content based on its meaning.
Can AI handle documents in multiple languages?
Yes. Many AI systems support multiple languages and can sort documents written in different scripts, ideal for global teams.
How secure is AI document classification?
These systems come with strong security features like encryption, role-based access, and compliance with privacy laws to protect sensitive data.
How does AI document classification work with other systems?
It connects easily with tools like DMS, ERP, or CRM, so teams don’t need to change their current workflows.
Can AI models be tailored to specific needs?
Yes. You can train models on your own data to match your business goals and improve accuracy for your documents.